
글또 활동을 하며 자극을 받아서 '나도 멋드러지게 논문 리뷰 한번 해봐야겠다!!' 라는 생각을 하게 되었습니다. 물론 요새 논문을 많이 읽는 것도 있지만요.
오늘 다룰 주제는 최근 Pruning의 시초 격인 Learning both Weights and Connections for EfficientNeural Networks 논문입니다. 뭔가 누구나 생각할 수 있었을 것만 같은 간단한 방법으로 큰 효율을 낸 멋진 논문이라 생각이 되네요. 함께 알아보는 시간이 되었으면 좋겠습니다.
이 논문은 이 링크에서 확인을 할 수 있습니다.
1. Introduce
인공지능의 발전으로 인하여 다양한 곳에서 ML에 관한 수요가 늘어나고 있다. 하지만 Deep Learning의 특성 상 굉장히 집약적인 특성을 보이고, 그렇기 때문에 임베디드 시스템에 배치하기 어려운 면이 있다.
이 논문에서는 위와 같은 문제를 해결하기 위하여 3단계로 Accuracy의 손실 없이 네트워크 연결을 제거하는 방법을 제시한다.
첫 번째 단계는 어떤 연결이 중요한지 배우고 중요하지 않은 연결은 제거한다. 그런 다음 남은 연결이 제거된 연결을 보상할 수 있도록 네트워크를 재교육한다. 그 후, 거의 사용되지 않는 연결을 점진적으로 제거하여 지속적으로 나아가는 형태를 보인다.
2. Pruning
위에서 설명했던 중요하지 않은 연결을 제거하는 과정을 Prune이라고 지칭하며, 이 일련의 과정들을 Pruning이라고 말한다.
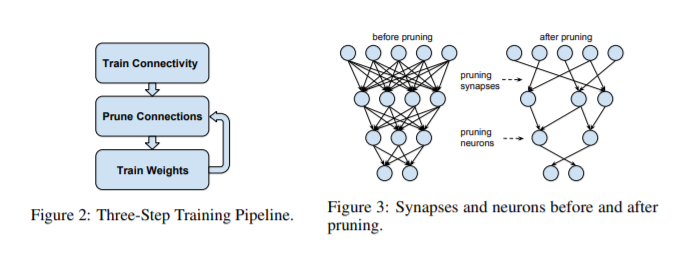
위 그림이 Pruning을 너무나 잘 설명해준다고 생각한다. Figure 2와 같이 3단계로 이루어져 원하는 수치에 도달할 때 까지 반복하여 시행한다.
Figure 3은 Pruning이 일어난 Network를 보여주는데, 필요하는 연결을 제거하며 사용되지 않는 유닛 또한 제거하여 경량화를 향해 간다고 해석할 수 있다.
3. Learning Connections
이 파트에서는 Pruning을 수행하는 방법을 더욱 자세하게 알아보도록 하겠다.
3.1 Regularization
Regularization은 Overfitting을 잡기위하여 Cost Function에 특정한 값을 추가 연산해주는 작업을 말한다. 이 때 특정 값을 찾는 과정에서 L1 norm을 사용하는지, L2 norm을 사용하는 지에 따라서 L1 Regularization / L2 Regularization으로 나뉜다.

실험에 따르면 L2 Regularization이 전체적으로 좋은 성능을 보여주었으며, 효율적으로 줄여나갈 수 있었다. 하지만, 재교육하기 전에는 L1 Regularization가 좋은 성능을 보여주었다.
3.2 Dropout
Pruning이라는 개념을 처음 들으면서 가장 궁금했던 부분이었다. 연결을 제거해 나가는데, 이후 Dropout에는 영향이 없는지, 영향이 있다면 Dropout을 사용해도 되는 것인지 궁금했었다.
이 논문에서는 Pruning의 진행에 따라서 비율을 조절해나간다고 밝혔다.
Dropout과 Pruning은 비슷하게 학습 중에 연결이 삭제되지만, Pruning은 영원히 사라지고, Dropout은 진행과정에서 다시 나타난다는 큰 차이점이 있다.
위와 같이 어떠한 Parameter가 영원히 사라진다면, 그에 따라 Dropout의 Rate를 조정해야 할 것이다. 그 방법을 논문에서 아래와 같은 식으로 설명을 하였다.

- Ni = 레이어 i에서 Neuron의 수
- Ci = 레이어 간의 연결의 수
- Dr = 재 학습 되며 조정된 Dropout Rate
- Do = 원래의 Dropout Rate
이런 식으로 감소해 나간다고 알 수 있다.
3.3 Local Pruning and Parameter Co-adaptation
Prune후 재학습 시에 초기화를 하지 않고, 현재의 weight를 유지하는 것이 좋다고 말한다. 이는 CNN의 fragile co-adapted(공동 적응형..?)한 특성 때문인데, 이 논문(How transferable are features in deep neural networks?)에서 이와 같은 의견을 확인할 수 있다.
또한, 학습과정에 Gradient Vanishing을 방지하기 위하여 FC와 FC가 아닌 레이어를 구분하고 나누어서 Prune을 진행했다고 밝힌다.
초기의 Weight를 저장하고 있다가 Prune 후 retrain 전에 초기의 weight로 돌려주어야 한다는 “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks” 논문과 대비되는 느낌이라 흥미롭네요.
3.4 Iterative Pruning
올바른 연결을 찾기 위해서는 반복적으로 수행해야만 한다. 반복을 많이 한 후에 최소의 네트워크를 찾을 수 있었다.
각각의 반복은 최고의 연결을 찾는다는 점에서 Greedy Search라고 볼 수 있다고 밝힌다.
또한, 실험 과정 중에 absolute value를 사용하여 실험을 진행해보았지만, 좋은 결과를 얻을 수 없었다고 전한다.
3.5 Pruning Neurons
연결을 제거하면 Neuron은 걱정할 필요없이 Retrain 과정에 Prune 된다. 이는 Input 연결이나 Output 연결이 0인 Neuron(Dead Neuron)은 연산과정에서 자동으로 다른 한쪽도 0이 되는데, 논문에서 이러한 변화의 원인을 Gradient Descent와 Regularization이라고 한다.
그런 결과가 나타나는 이유를 생각해보면, 한 쪽이 0이 된다면 추가적이 업데이트가 없는 연결은 자연스레 Vanishing Gradent가 일어나며 0으로 수렴할 것이다. 지속적으로 0으로 수렴하다가, Weight에 패널티를 부여하는 Regularization으로 인하여 최종적으로 0이 되어 활동하지 않는 Neuron이 되리라고 생각한다.
'기타' 카테고리의 다른 글
| Grafana '/var/lib/grafana/plugins': Permission denied 오류 해결 (1) | 2021.02.06 |
|---|---|
| Detection Algorithm (0) | 2021.01.09 |
| Docker Hub 무제한 종료?? (0) | 2020.11.04 |
| Happy Halloween! / 호박밭? 시든 잔디밭? (0) | 2020.10.31 |
| GitHub Actions Workflow의 Event Trigger(On, Schedule) (0) | 2020.10.24 |




댓글